Appearance
全自动反驳扣字软件?
 据笔者观察 最近喷系频繁出现宣称能够“全自动反驳、自定义词汇、释放双手”的扣字对线软件。此类软件通常以极低的价格(如 38 元永久使用)进行商业化兜售,并标榜其具有“无破绽、全自动”的对抗能力
据笔者观察 最近喷系频繁出现宣称能够“全自动反驳、自定义词汇、释放双手”的扣字对线软件。此类软件通常以极低的价格(如 38 元永久使用)进行商业化兜售,并标榜其具有“无破绽、全自动”的对抗能力
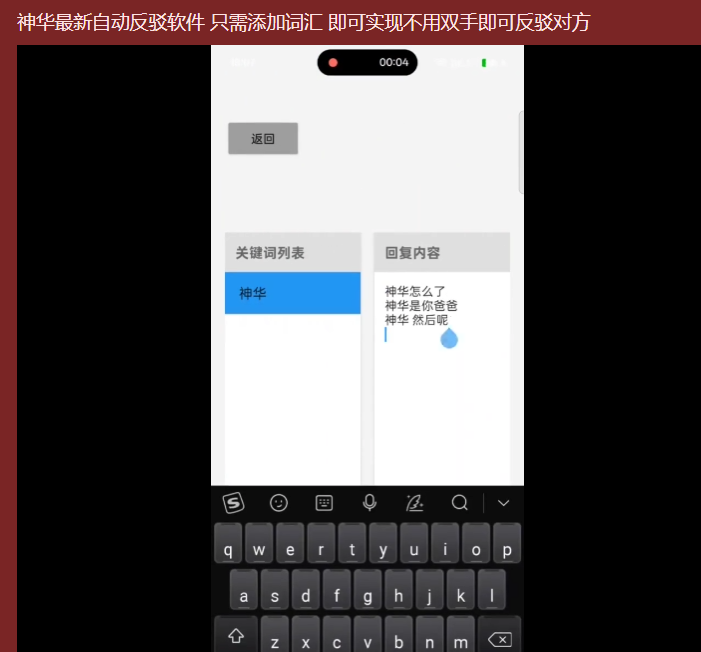 看到此处,笔者不由感到好奇。从其实机运行界面来看,其所谓的“智能化”后台不过是极其简陋的单向映射结构:左侧为固定的“关键词列表”,右侧为死板的“回复内容”。 这种纯粹从本地有限的文本库中,随机或按顺序提取一行预设文本来匹配关键词的机制,何谈真正的“全自动反驳”?
看到此处,笔者不由感到好奇。从其实机运行界面来看,其所谓的“智能化”后台不过是极其简陋的单向映射结构:左侧为固定的“关键词列表”,右侧为死板的“回复内容”。 这种纯粹从本地有限的文本库中,随机或按顺序提取一行预设文本来匹配关键词的机制,何谈真正的“全自动反驳”?
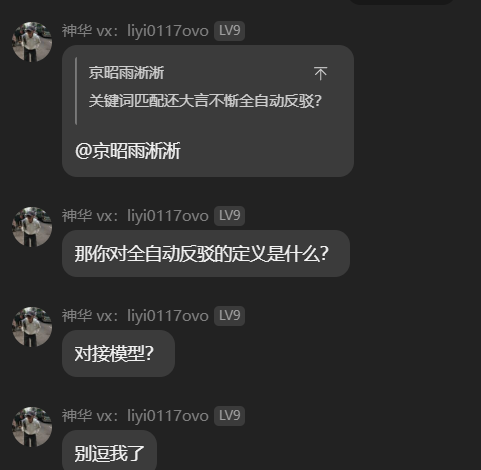
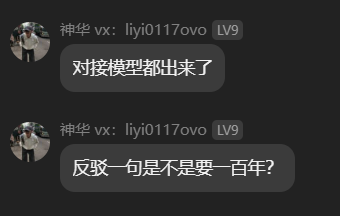 在关于“全自动反驳”的实际对线中,此类软件的贩卖者在面对“对接模型、中转站、破甲”等标准的现代后端架构术语时,表现出了极强的技术脱节并提出了极具技术盲区的质疑:“对接模型都出来了,反驳一句是不是要一百年?”
在关于“全自动反驳”的实际对线中,此类软件的贩卖者在面对“对接模型、中转站、破甲”等标准的现代后端架构术语时,表现出了极强的技术脱节并提出了极具技术盲区的质疑:“对接模型都出来了,反驳一句是不是要一百年?”
看到此处,笔者认为有必要从计算机网络与高并发架构的专业角度,对此类无知言论进行纯技术科普:
- 现代大模型 API 的流式中继与毫秒级响应
该类观点误以为大模型的文本生成依旧停留在早期本地离线跑超大参数、单句渲染极慢的原始阶段。事实上,现代基于 NoneBot2 中继架构 + 高性能 LLM 大模型 API 的交互系统,其运行效率早已实现了质的飞跃:
流式传输(Streaming):模型在接收到文本后,采用逐字/逐 Token 异步输出机制,首字响应时间(TTFT, Time to First Token)通常可以卡定在 200ms - 500ms 之间
- 对抗策略的升维与底层开发生态的暴露
在技术对线的后半段,面对现代大模型中继架构的客观优势,此类脚本贩卖者因无法在架构层面进行合理解释,转而抛出“那你去写一个免费发出来不就好了”的非技术性言论。
对此,笔者进一步对文本对抗中的推理性能调优以及此类低端软件的真实底层生态进行了深度的工程学审视:
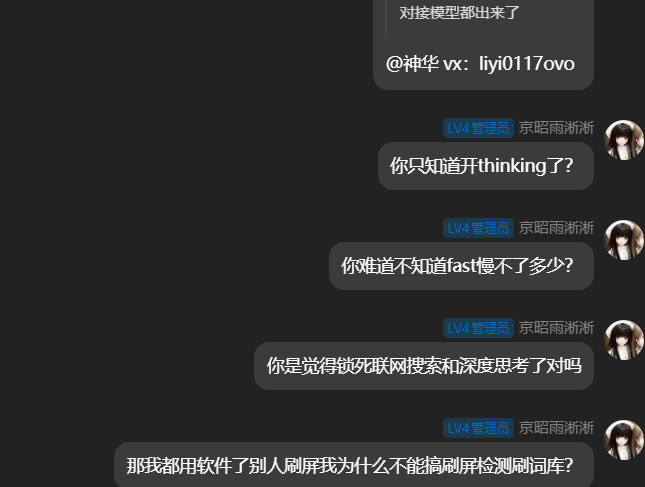
- 该类软件开发者对现代 LLM 的认知极其狭隘,误以为调用大模型系统必须开启“联网搜索”或“深度思考(Thinking)”等高延迟的长推理模式 事实上关闭了思考层、纯流式输出的 Fast 快速模型。其延迟开销极低,在毫秒级差距下,其生成的文本逻辑连贯性对关键词脚本具有压倒性的优势
- 开发语言的生态代差 在被问及底层技术栈及“是否爱用易语言开发”等核心问题时,对方采取了装死和避而不谈的规避态度。 这一现象直接暴露了此类“全自动反驳软件”背后的灰产开发生态:
易语言组件拼凑:此类软件绝大多数并非基于现代主流、具备强大生态支持的后端语言(如 Python、Go 等)编写,而是依赖早已被现代软件工程边缘化的易语言。其本质是利用易语言现成的字符串匹配支持库,套一个极为简陋的 UI 壳子拼凑而成。由于开发者自身不具备现代网络架构与大模型 API 中转站的开发能力,因此在面对“对接模型”等现代技术术语时,除了进行非理性的抵触外,无法提供任何实质性的代码级逻辑支撑。
结语
笔者声明
这种垃圾东西我都懒得写。
垃圾脚本贩卖者不仅在逻辑和架构上存在严重的认知断层,其赖以生存的技术底层更是在被点穿“易语言”后彻底失去了伪装的价值。拿无意义的死词库刷屏去碰瓷流式高并发的现代大模型,最终只能在本站变成奇异搞笑的挂人素材。